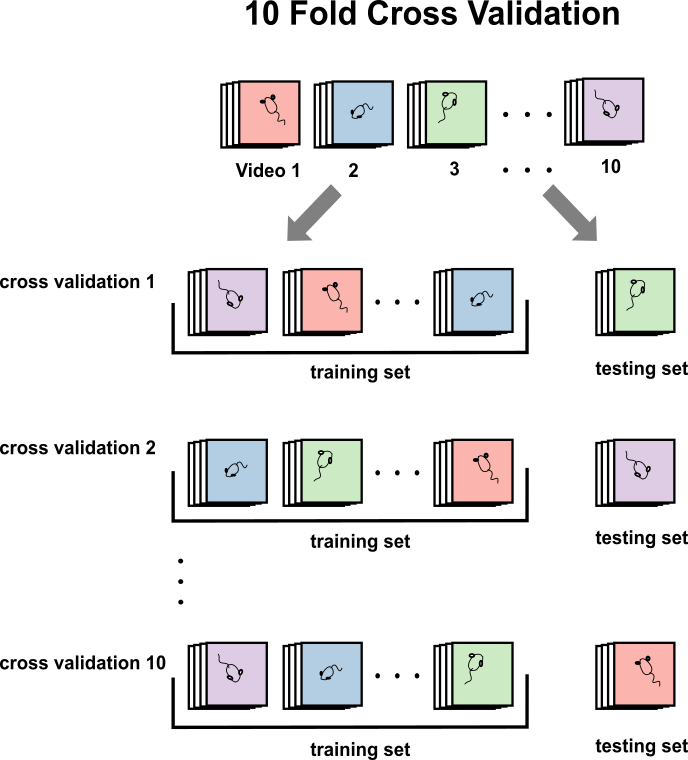
Cross Validation
In cross validation, the classifier is trained on a set of labels (training set), then tested on a set of labels held-out of the training set (testing set). This is used to estimate the accuracy of the classifier.
In Rotta, we use a 10-fold cross validation technique. Here, the classifier is trained on a training set of 9 labeled videos and tested on a testing set of 1 randomly selected video. The accuracy of the classifier is recorded. This process (training on 9 videos and testing on 1 held out video) is repeated 9 more times until each video has been the ‘test’ video. The mean and median of the accuracies across all trials are used as an estimation of the classifiers accuracy.
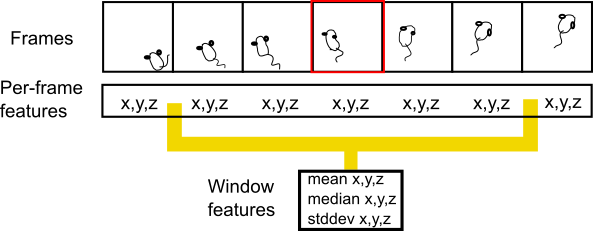
Window Size
Rotta works by computing features at each frame of a video based on the the coordinates of important body points on the mouse. The label given by the user for each frame is used to train a classifier. The ‘inputs’ for training a classifier are an important consideration, especially for time structured data; behaviors we would like to classify occur over variable lengths of time. Having the classifier train only on one video-frame at a time leaves it vulnerable to noise (or incorrect frame labels) and the classifier loses out on information about the transitions from frame to frame which make up a behavior. Window size helps improve the classifier by determining the amount of frames we want the classifier to look at to learn the behavior. Rotta computes window features, which are statistical measures of all the per-frame features inside that window. For example, if the window size is 6, Rotta looks at 6 frames around a labeled frame, computes window features using all those per-frame features, and then trains using window features. For a shorter behavior, the ideal window size may be small, while for a longer behavior, it may be large.